
02BBQ
[궁금했던 녀석들~ 여기여기 붙어라~!!] 딕셔너리, 넌 누구냐고~ c# Dictionary 내부구조 (dic)
02BBQ
2025. 11. 11. 15:22
안녕하세요. 오늘은 닥셔너리 내부 설명하겠습니다. 하하하하

딕... 딕셔너라ㅣ 내가 안다고~ 딕셔너리 그거 해시 테이블이랑 버킷 그거 머시기 아니냐고~ 내가 안다고 딕 주세요 딕 ㅠㅠㅠㅠ 깁미 엔젤 딕

아니 😇😇 그래서 그게 뭔지 아냐 이😶🌫️😶🌫️😶🌫️들아
오늘은 딕셔너리 깊게 설명 갑니다. 후훌후후후후.
여러분 감기 조심하세요.
알아야하는 기본 지식: 기본 c# Dictionary 생김새 정의하고 사용법 설명 안함
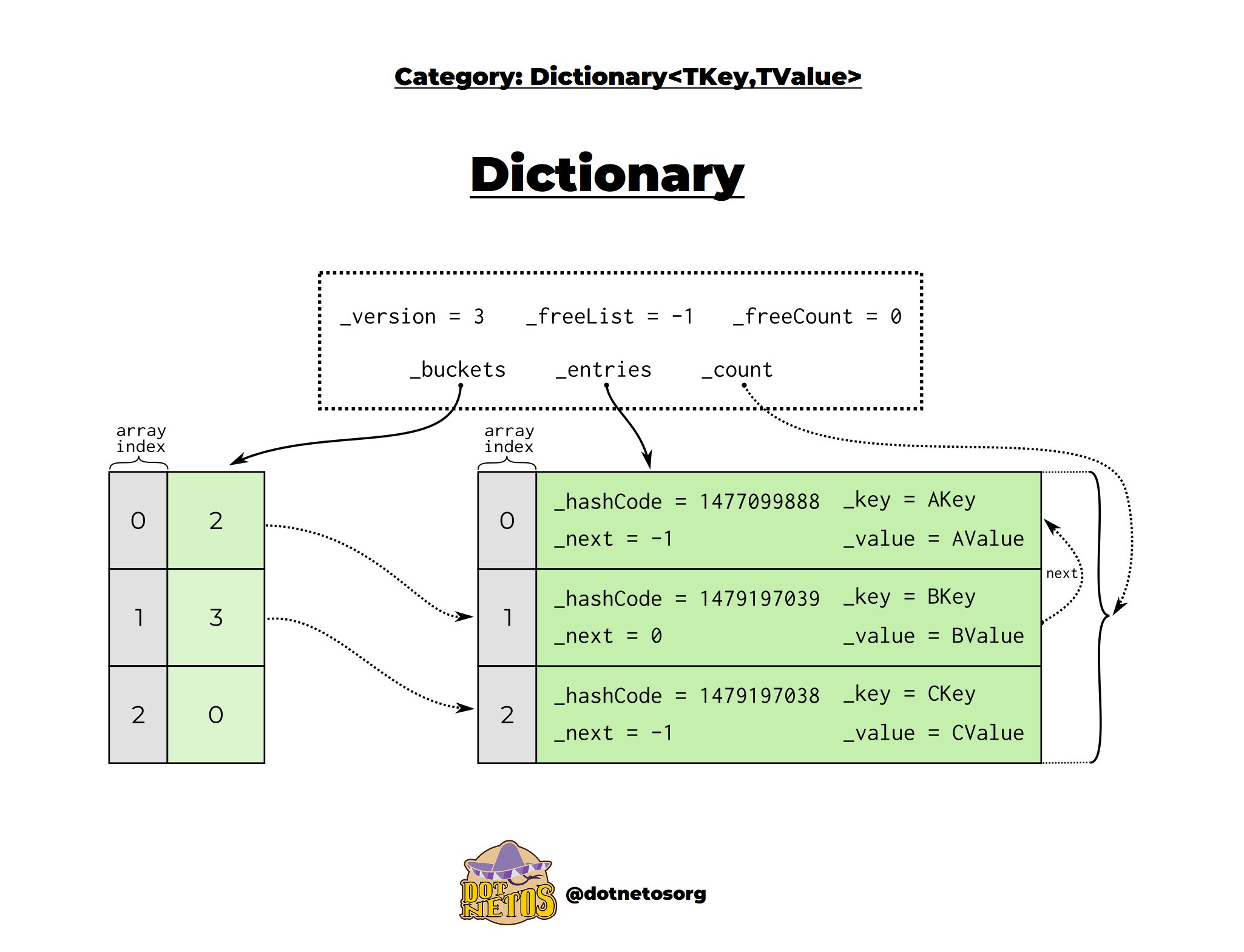
안녕하세요 c# dictionary는 이렇게 생겼습니다. (실제임)
이 버킷들과 엔트리들로 구별되어있습니다.
잠시만 그럼 해시 태이블은 어디 있지? 어 그게 엔트리들이여.
Entries 배열 설명 (진짜 설명함)
해시 테이블이라고 흔하게 부른다.
일단 엔트리들 배열에는 엔트리 구조체가 들어갑니다. 엔트리는 걍 요소인.
Entry[ ] 임

그냥 딕셔너리에 값을 넣으면 얘한테 일단 다 들어간다. 그리고 버킷을 통해 찾을걸 찾음.
엔트리는 일단 hashCode, key, next, value로 이루어져 있음
그 님들이 값 넣으면 키랑 벨류 뭐 해시 다 얘가 가지고 있음.
hashCode는 이 요소녀석의 (줄여서 요녀석) Hash값이 들어가 있다. 해쉬 브라운 먹고싶노.
Hash값은 이 녀석녀석들을 Key를 숫자로 변환해주는 해시 함수를 통해 나온 값입니다 ㅎㅎㅎㅎㅎ

그 다음 Key가 있는데 이건 그냥 딕셔너리 키요.
그 다음엔 next인데 next는 next time에 설명할께요;;;;;;
value는 키와 쌍쌍바인 값입니다. 걍 니가 넣은거다.
근데 이게 해시함수를 죠지면 해시값이 동일한 경우가 있습니다잉...
이건 뭐 막을수가 ㅇ없고 이 상황을 해시 충돌이라고 한다.

이거 때문에 이제 해시로 찾는건 안되고... 아무튼 해시 충돌을 방지하는 방법은 많지만
C#딕셔너리가 이용하는 방법은 앙 해시 체이닝이다.
해시 체이닝이 뭐요?
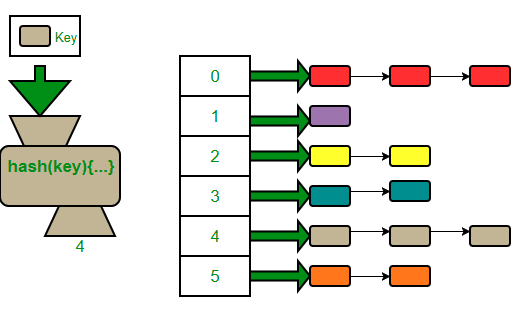
앙 그냥 linked List처럼 다음거 가르키는 것이여 중복끼리.
저 엔트리의 next 변수는 겹치는 값의 해시테이블 내부 인덱스 위치를 가르키다;;;;
좀따 더 설명함.
OK 이해 됬노
버킷은뭐고 (Buckets) (진짜로 알려줌)

일단 그냥 아주 아주 아주 간단한 int[]이다. (정수 배열)
버킷은 엔트리 배열에 특정 엔트리의 인덱스를 가르키는 배열이다.
엔트리의 해쉬코드 % 버킷 크기 인덱스에서 해당 엔트리의 해시테이블에서의 index + 1을 int로 가르킨다.
그냥 이 가르키는 것들의 모임 배열.
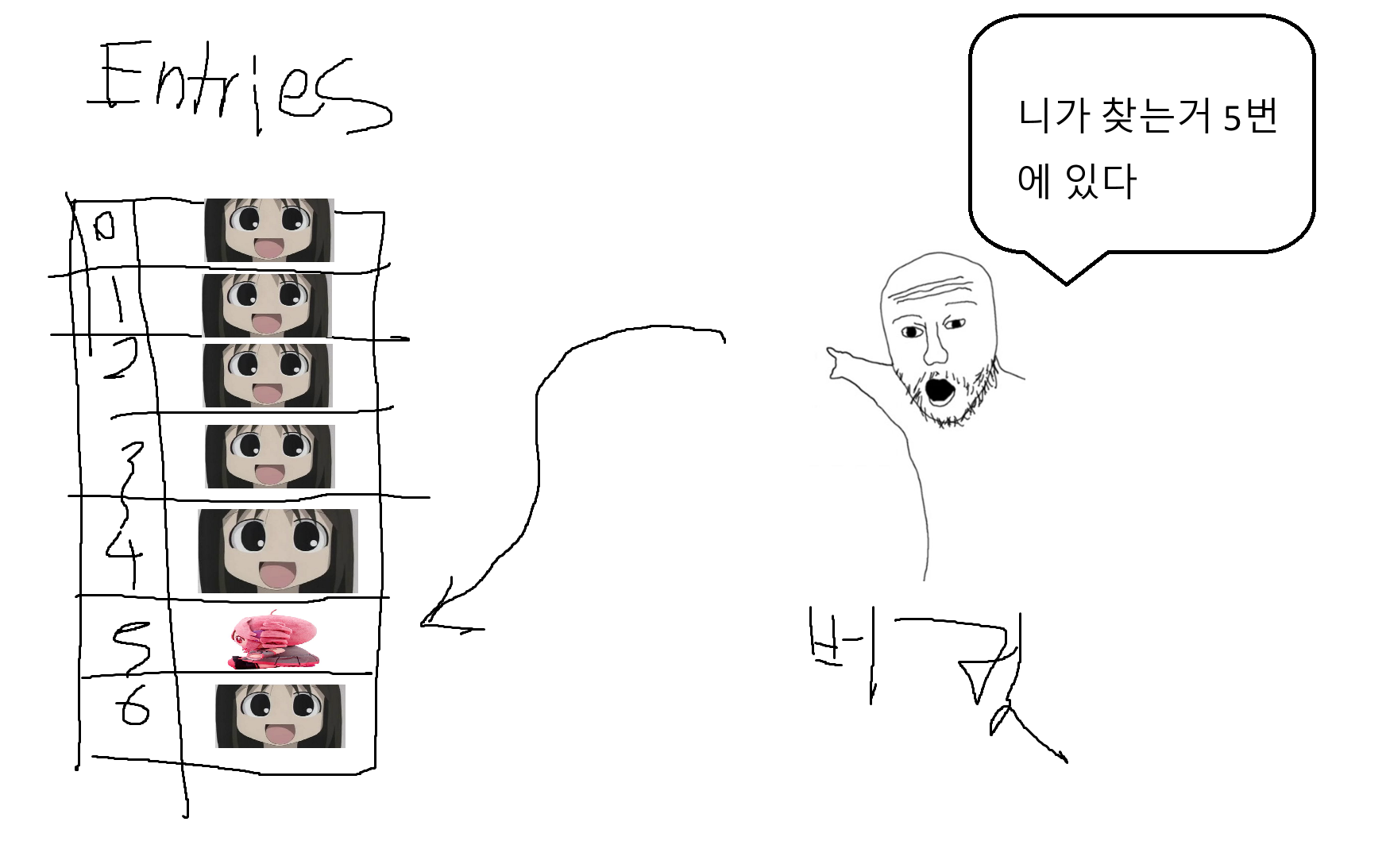
Add Find Remove 다 얘를 통해서 타깃을 찾는다. (또는 추가)
딕셔너리 조회할때 버킷을 통해서 조회한다.
또한 버킷의 크기는 무조건 소수이다. (Prime Number) (성 소수자 아님)
끝.
이면 굉장히 섭섭해 버리지 음.
버킷에 관한 끔찍한 진실들...

그래서 버킷은 왜 소수고 뭘 가르키고 그 기준은 뭐고 다 설명 가자잉.
일단 버킷은 아까도 말했듯이 엔트리의 인덱스 + 1의 값이 들어간다.
왜 +1이냐? 0이 비어있다는 의미이기 때문에 인덱스에 1을 더한다;;
기본값이 0임.
뭐 아무튼 그래서 인덱스를 표기하는데 인덱스를 표기하는 기준은 뭐냐.
엔트리의 해쉬코드 % 버킷 크기의 값이 들어간다.
예를 들어 해쉬코드가 9인 엔트리가 있으면, 들어올때 버킷에도 들어오는데,
버킷의 크기가 7이라면 9 % 7을 한 값인 2번 째 버킷 인덱스에 이 엔트리의 인덱스가 들어간다.

오케이 오케이 이해함. 이건 이해 해야한다.
근데 만약에 Hashcode % Bucket Size가 = 같다면?
새로운 엔트리를 추가하는데 이번에도 이 나머지 값이 2라면...
그럼 2번 이 가르키는 1번 엔트리를 찾는다. 그리고 이 친구의 _next로 새 엔트리를 넣는다.
만약 _next가 이미 있다면 그것의 _next로 넣는다.
그래서 딕셔너리의 add는 O(1)의 시간 복잡도를 가지지만, 최악의 경우 O(n)의 복잡도를 가지게 된다.
(최악의 경우: 엔트리 n개인데 n개가 전부 다 버킷 2번칸에 들어간 경우.)
탐색도 동일하다.
오케이 이것도 이해됐다.
그럼 버킷의 크기가 무조건 소수인 이유도 알 수 있다.

바로 소수로 나누면 값이 겹치는 경우가 덜해진다.
약간 오바하자면.
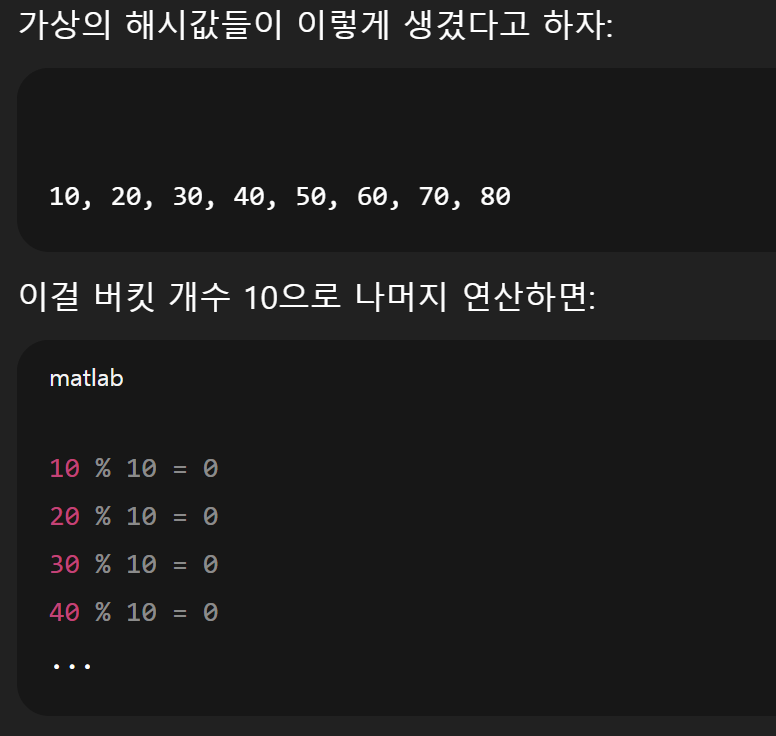
어 걍 귀찮아서 GPT 시킴.

대충 이런 이유로 앙 소수띠로 크기를 정한다.
자 근데 이게 버킷이 뭐 크기가 고정이면 탐색이 굉장히 비효율적으로 이루어 질 수 있다.
그래서 동적으로 크기를 조절한다.
오케이 이것마저도 이해했다 칭찬해~

자 근데 크기를 어떨 때 조절할까??
음... 꽉찼을 때?
아님.
버킷의 내용물 갯수와 버킷의 전체 크기의 비율이 약 0.72정도 일때 늘린다.
(Entry 수 / Buckets Size) = 로드 팩터
자 일단 왜 그때인지 설명함.
앙 기모띠 |
로드 팩터가 작을 때 (내용물 적음) | 로드 팩터가 클 때 (내용물 많음) |
| 충돌 | 적음 | 많음 |
| 메모리 | 낭비 심함. | 효율적이다 ㅎㅎ |
| 조회 속도 | 빠름 | 느림 |
이렇기 때문에 밸런스를 잘 맞춰야한다. 이 기준을 약 0.72로 두면 딱 적당하다.
약 0.72인 이유를 알아보자.
해시 테이블에서 평균 탐색 횟수(체인 길이)는 로드 팩터 α에 대해
- 탐색 성공 시 평균 비교 횟수: ½(1 + 1/(1 - α))
- 탐색 실패 시 평균 비교 횟수: ½(1 + 1/(1 - α)²)
로드팩터가 0.72 일 때.
성공 시 평균 비교 횟수 = ½(1 + 1/(1 - 0.72))
= ½(1 + 1/0.28)
= ½(1 + 3.57)
= 2.285
2.285번의 비교로 탐색 가능!! (뭐 나쁘지 않음)
0.9일 때:
½(1 + 1/(1 - 0.9)) = ½(1 + 10) = 5.5
5.5번 탐색해야함 (매우 비효율적)
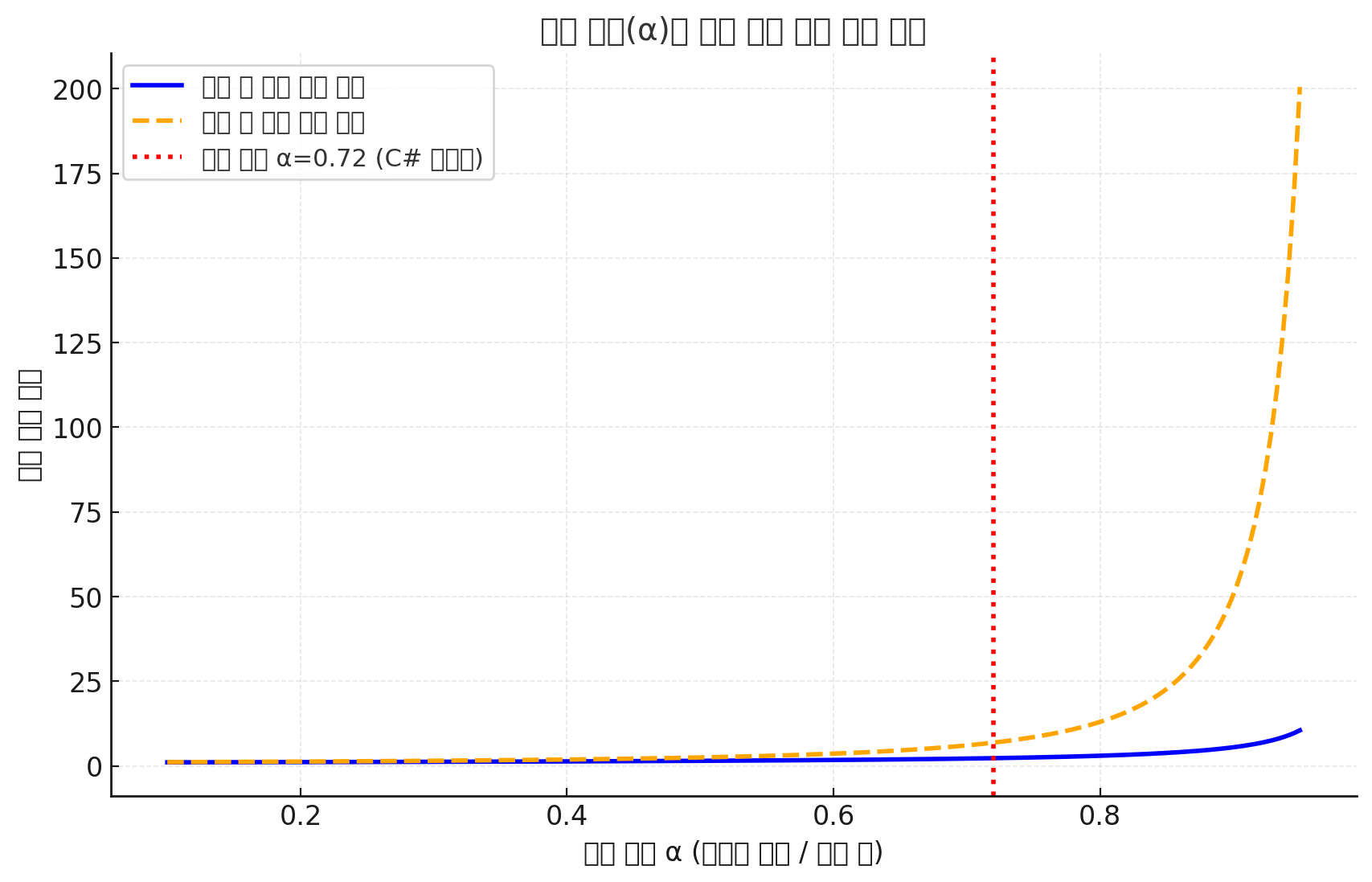
겁나 깨지긴 했는데 파랑은 탐색 성공 시 비교 횟수고 노랑은 실패시 비교 횟수다.
아무튼 저렇게 급격하게 느려질 수 있음. 그래서 실패도 안전한 앙 약 0.72라는 수치로 정한 것이다.
로드팩터가 약 0.7을 넘으면 다음 소수 크기의 배열을 새로 만들고 모든 엔트리들의 hash를 다시 나누어 새 버킷을 만든다.
그렇다 Resize는 당연히 무겁다.
와 이거까지 이해함;; 나이스요;;
Resize
아 참고로 Entries와 Buckets는 크기를 약간 공유하기 때문에~ 같이 리사이즈됨.
뭐 사실상 거의 끝났다. 이게 딕셔너리 내부 구조다. 근데 남은게 있다.

이것들은 딕셔너리의 변수들이다.
얘네는 뭐지?
딕셔너리의 버젼
일단 _version. 얘는 걍 dictionary의 변경이 일어나면 1씩 오른다.
존재하는 이유는 foreach중에 dictionary가 변경되면 오류를 내야한다. (뭐 없어졌다거나 추가한다거나 등등)
이 변경됬는지의 감지를 version을 통해서 알아낸다.
var dict = new Dictionary<string, int>();
dict.Add("A", 1);
dict.Add("B", 2);
foreach (var kv in dict)
{
dict.Add("C", 3); // 여기서 구조가 바뀜 → _version++
// → InvalidOperationException 발생
}오케이 그래 이해했다.
_freeList
freeList는 해시 테이블에 요소를 추가할 때 사용된다.
딕셔너리에 Remove를 사용하여 중간에 빵꾸를 냈다고 가정해보자.
그럼 걍 freeList가 빵꾸를 가르킴.

근데 이게 freeList인데 걍 int인 이유는...
이것도 링크드 리스트 형식으로 빈공간을 가르킨다.
.Remove()는 실제로 엔트리를 삭제하지 않는다.
엔트리의 Hash를 -1로 변경하고, bucket에서 빼낸다.
즉 해시 테이블에는 남아있는 것이다.
그리고 next에는 이전 빈공간이 있다면 (freeList)를 가르키고 freeList를 그 엔트리의 인덱스로 변경한다.
.Add()를 진행하면 freeCount를 비교하여 free 공간이 있는 것이 확인되면 freeList위치에 새로운 엔트리를 넣는다.
_freeCount
위에 일이 일어날때 freeList 즉 남은 공간이 있는지 어케 판별하는가? 이 _freeCount가 해준다.
걍 freeList있냐 없냐 판별해주기 위한 Flag이다.
앙 마지막으로
_count
걍 엔트리 수이다. 로드팩터 구할 때도 사용하고 기본적으로 Add시
엔트리를 해쉬테이블의 맨 뒤에 넣기 때문에 맨 뒤 인덱스를 의미하기도 함.
탐색
탐색은 어케 진행되냐면 일단 hashcode를 버킷의 크기로 나눠서 해쉬 테이블에서 첫번째 값을 찾는다.
그다음 그 엔트리와 해시 값을 비교한다. 다르면 next를 통해 다음 값과 비교한다 (있으면)
만약 해시 값이 같아도 이게 걍 충돌일 수 있기 때문에 key를 비교함. ㅋㅋ
그래서 좋으면 O(1)인데 걍 최악은 O(n)임. 🤷♀️
끝
오늘은 똥글 없음